Fases del proceso de análisis de datos de la certificación Data Analytics de Google
Estas son las fases del proceso de análisis de Datos según la certificación profesional de Data Analyst de Google en Coursera. Las cuales voy a ilustrar con un ejemplo de un proyecto de análisis de datos sobre mi contenido visto en Netflix que realicé previamente.
@mkfnx Analizando tu info de #Netflix con #python y bibliotecas de #datascience #cienciadedatos ♬ sonido original - Miguel
Hacer preguntas (Ask Questions to Make Data-Driven Decisions)
Esta fase se refiere a hacer preguntas a tomadores de decisiones de la institución con que estemos trabajado con el fin de definir los problemas a los que queremos dar solución con nuestro análisis y los alcances de la misma. Normalmente los objetivos de la empresa estarán relacionados al negocio por ejemplo podría querer conocer predicciones de ventas de algún producto.
En mi ejemplo no estaba trabajando con una institución, mis objetivos eran practicar mis habilidades con las bibliotecas de Python para Ciencia de Datos y crear contenido interesante para mi cuenta de TikTok. Aunque en algún momento gente de Netflix pudiera querer realizar un análisis similar para crear visualizaciones para sus clientes como hace Spotify con su Year in Review.
Preparar los datos para exploración (Prepare Data for Exploration)
Esta fase consiste principalmente en recolectar los datos que necesitamos para nuestro análisis, los datos pueden venir de muchas fuentes y en distintos formatos. En ocasiones puede que no exista un recurso listo para consumo y entonces tendríamos que generar o recolectar la información nosotros mismos, por ejemplo con una encuesta o creando nuevos registros de información en nuestros procesos o sistemas.
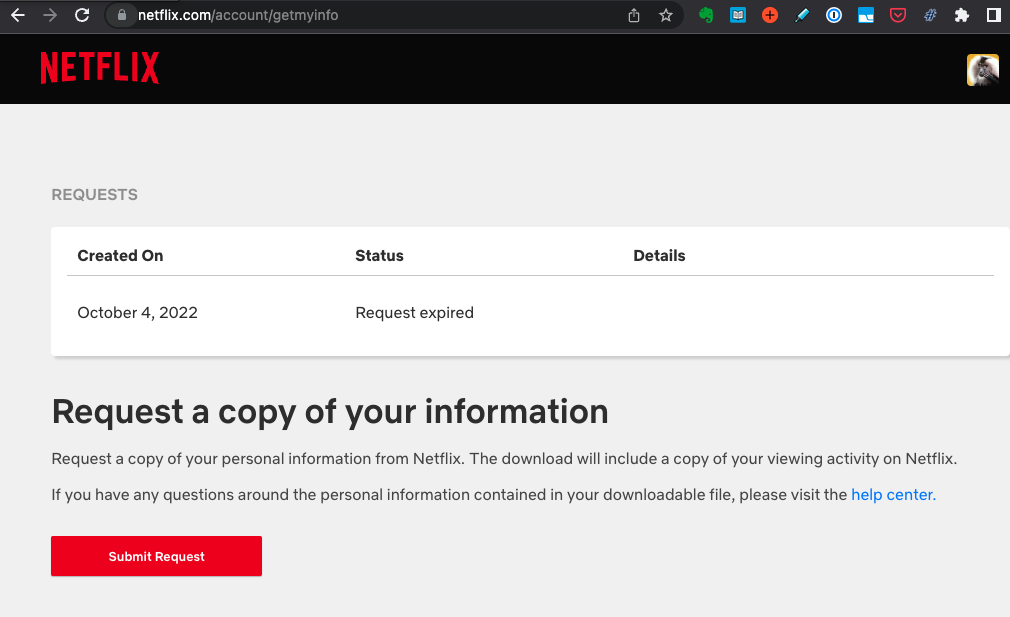
Mi ejemplo de Netflix lo realicé con la información personal de mi cuenta y esta información se puede solicitar a Netflix en la sección de tu perfil de tu cuenta. Unos días después ellos enviarán tu información a tu correo.
Limpieza de datos (Process Data from Dirty to Clean)
En esta fase se hace una exploración inicial de los datos con el fin de encontrar errores en el formato de la información como datos faltantes, errores de captura, registros posiblemente erróneos, entre otros. Las herramientas de software para Ciencia de Datos cuentan con funciones que nos pueden ayudar en este proceso.
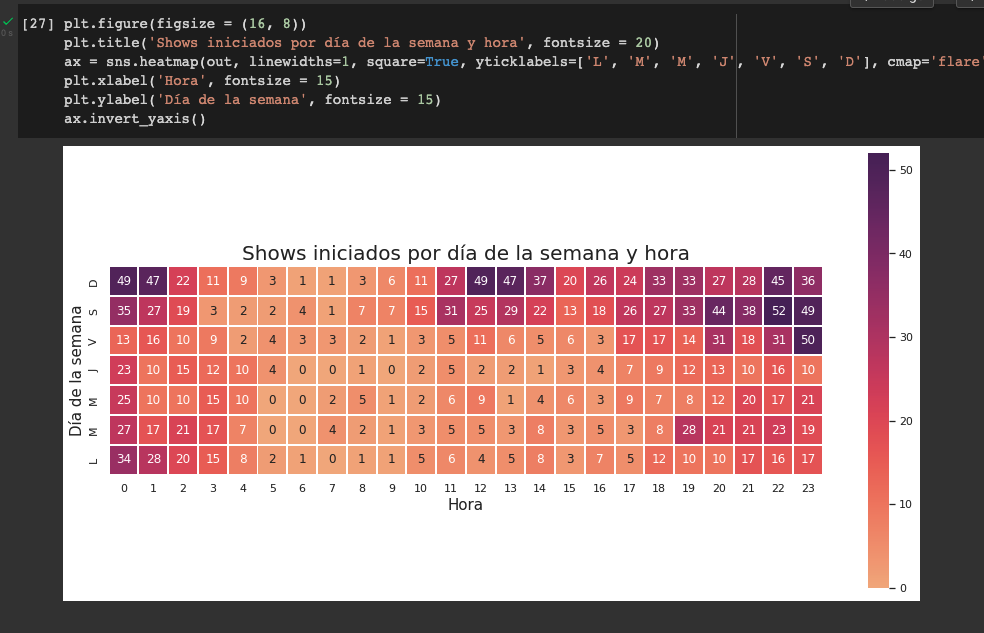
Analizar datos para responder preguntas (Analyze Data to Answer Questions)
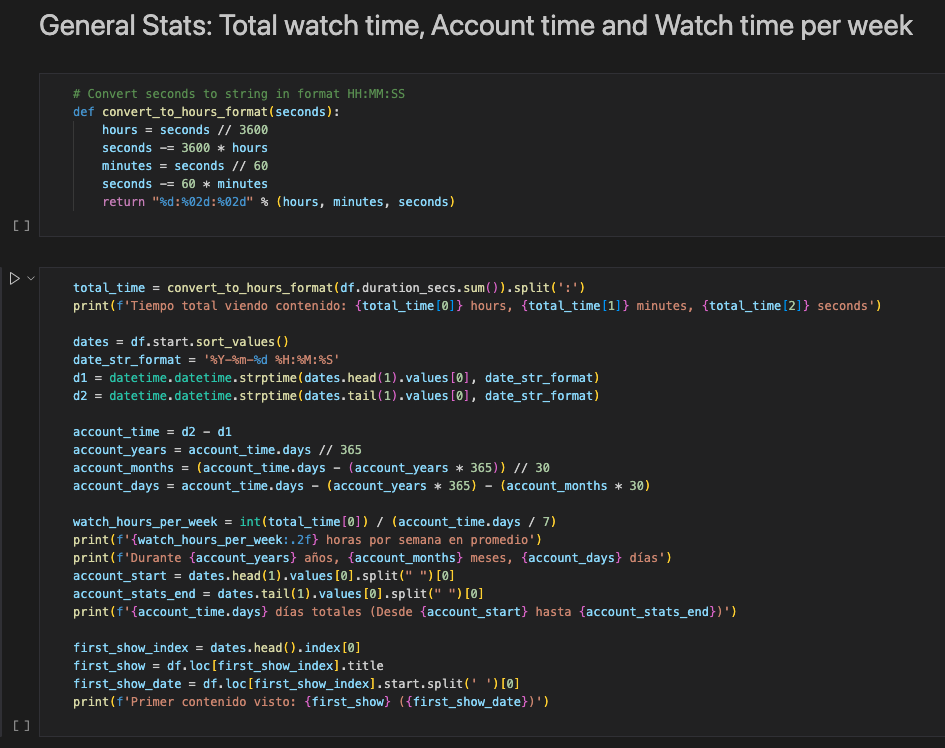
Aquí se realizan algunas de las actividades más significativas del proceso, pero que no serían posibles sin una buena ejecución de las otras fases. Aquí es dónde realizamos manipulación de datos para transformarlos en la información que da solución a los problemas que definimos inicialmente, para esto usamos herramientas de software como Excel, SQL, Python o R además de paquetes o bibliotecas que complementan estas herramientas como Pandas para el caso de Python.
Compartir hallazgos usando visualizaciones (Share Data Through the Art of Visualization)
En esta fase se crean visualizaciones de datos con el fin de compartirlos con tomadores de decisiones y otros involucrados y así ellos puedan entender los resultados de nuestro análisis con mayor facilidad. Aquí usamos algunas otras herramientas especializadas en visualizaciones como Matplotlib, Seaborn, Tableau o Power BI.